Návod na instalaci Stable Diffusion 2.0 pro Automatic1111 WebUI
Firma Stability AI, která se podílí na vývoji Open source projektu Stable Diffusion oznámila 24.11. 2022 vydání nové verze 2.0 tohoto projektu na generování obrázků pomocí AI z textového popisu. Oznámení vyvolalo nejprve velké nadšení u komunity, které ale posléze vystřídaly spíše obavy z některých zásadních změn a omezení u nového modelu, který byl trénován na jiném data setu s vynecháním části obsahu dostupném u předchozích modelů. Jak to nakonec dopadlo můžete vyzkoušet sami, pokud máte nainstalované Webové rozhraní Automatic1111, je po dvou dnech možné nahrát nový model Stability Diffusion v 2, návod jak postupovat najdete v tomto článku…
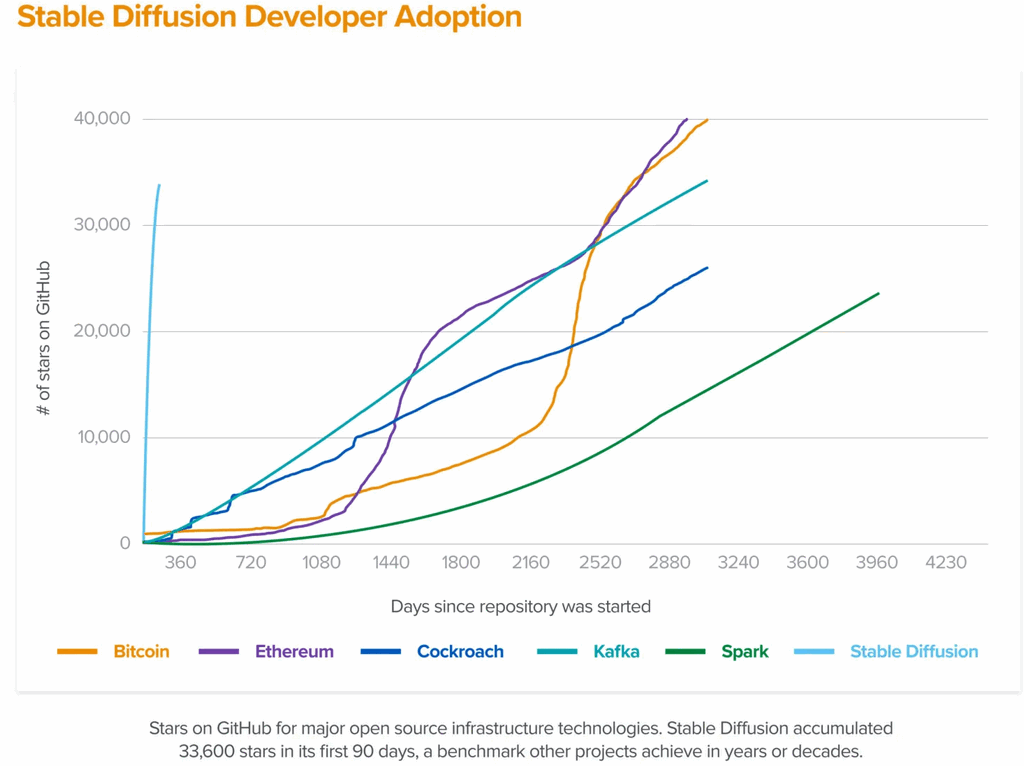
zdroj:a16z.com
Vyjádření Stability AI k vydání Stable Diffusion verze 2
Je pro nás potěšením oznámit vydání open-source verze Stable Diffusion 2. Původní Stable Diffusion V1 od společností CompVis změnila povahu open source modelů umělé inteligence a dala vzniknout stovkám dalších modelů a inovací po celém světě. Byl to jeden z nejrychlejších nárůstů na 10 tisíc hvězdiček na Githubu ze všech programů – za méně než dva měsíce dosáhl 33 tisíc hvězdiček.
Původní verzi Stable Diffusion V1 vedl dynamický tým Robina Rombacha (Stability AI) a Patricka Essera (Runway ML) ze skupiny CompVis na LMU v Mnichově pod vedením Prof. Dr. Björna Ommera. Navázali na svou předchozí práci v laboratoři s Latentními difuzními modely a získali rozhodující podporu od LAION a Eleuther AI.
Více informací o původní verzi Stable Diffusion V1 si můžete přečíst v našem dřívějším příspěvku na blogu. Robin nyní společně s Katherine Crowsonovou vyvíjí ve firmě Stability AI další generace mediálních modelů s naším rozšířeným týmem.
Stable Diffusion 2.0 přináší řadu velkých vylepšení a funkcí oproti původní verzi V1, takže se do nich pojďme ponořit a podívat se na ně.
Vydání Stable Diffusion 2.0 obsahuje robustní modely převodu textu na obrázky natrénované pomocí zcela nového kodéru textu (OpenCLIP), který vyvinula společnost LAION s podporou Stability AI a který oproti dřívějším vydáním V1 výrazně zlepšuje kvalitu generovaných obrázků. Modely převodu textu na obrázek v této verzi mohou generovat obrázky s výchozím rozlišením 512×512 pixelů i 768×768 pixelů.
Tyto modely jsou vytrénovány na estetické podmnožině datové sady LAION-5B vytvořené týmem DeepFloyd ve společnosti Stability AI, která je poté dále filtrována za účelem odstranění obsahu pro dospělé pomocí filtru LAION NSFW.
Difuzní model Upscaler se Super-rozlišením
Stable Diffusion 2.0 obsahuje i model Upscaler Diffusion, který čtyřnásobně zvětšuje rozlišení obrázků. Níže je uveden příklad našeho modelu, který zvětšuje rozlišení generovaného obrázku s nízkým rozlišením (128×128) na obrázek s vyšším rozlišením (512×512). V kombinaci s našimi modely pro převod textu na obrázek může nyní Stable Diffusion 2.0 generovat obrázky s rozlišením 2048×2048 – nebo ještě vyšším.

Depth-to-Image Diffusion Model
Náš nový model Stable Diffusion řízený hloubkou v obrazu, nazvaný depth2img, rozšiřuje předchozí funkci image-to-image z V1 o zcela nové možnosti kreativních aplikací. Depth2img zjišťuje hloubku vstupního obrázku (pomocí stávajícího modelu) a poté generuje nové obrázky s využitím textových i prostorových informací.
Můj komentář: v podstatě by měl nový model umět správně zachovat perspektivu výchozího obrázku, např. postavy v popředí a v pozadí i po změnách by měly mít stále stejnou věrnou perspektivu z původního obrázku, což byl často problém u ImgToImg modelu v 1.5…
Aktualizovaný Inpainting Diffusion Model
Zahrnuli jsme také nový model inpaintingu řízeného textem, vyladěný na novém základním modelu Stable Diffusion 2.0 pro převod textu na obrázek, který umožňuje velmi snadno a rychle inteligentně měnit části obrázku.
Stejně jako u první iterace Stable Diffusion jsme se snažili optimalizovat model pro fungování i na jedné grafické kartě – chtěli jsme ho od začátku zpřístupnit co největšímu počtu lidí. Už jsme se přesvědčili, že když se k těmto modelům dostanou miliony lidí, společně vytvoří opravdu úžasné věci. To je síla open source: využití obrovského potenciálu milionů talentovaných lidí, kteří možná nemají prostředky na trénování nejmodernějšího modelu, ale mají schopnost s ním udělat něco neuvěřitelného.
Tato nová verze spolu s novými výkonnými funkcemi, jako je depth2img a možnost zvýšení rozlišení, poslouží jako základ nespočtu aplikací a umožní explozi nového tvůrčího potenciálu.
Zdroj textu a obrázku: stability.ai
Návod na Instalaci Stable Diffusion v 2.0 lokálně pro Automatic1111 Stable Diffusion WebUI
Tento návod předpokládá, že už máte všechny potřebné součásti pro provoz Stable Diffusion nainstalovány a potřebujete jen zprovoznit nový model SD 2, pokud ještě nemáte na svém PC Stable Diffusion nainstalovaný, musíte nejprve provést celou instalaci popsanou v předchozím článku Stable Diffusion – AI generování obrázků.
Po úspěšném zprovoznění můžete přejít k instalaci nového modelu Stable Diffusion 2.
1. Nejprve si stáhněte soubor 768-v-ema.ckpt z této stránky, má kolem 5 GB, takže to nějaký čas zabere.
2. soubor 768-v-ema.ckpt zkopírujete do složky, kde máte nainstalované WebUI, konkrétně do složky models a její podsložky Stable-Diffusion
...\stable-diffusion-webui\models\Stable-diffusion
3. Stáhněte tento config (klikněte na něj zde pravým tlač. myši a dejte Uložit odkaz jako, musíte ho potom přejmenovat aby se jmenoval stejně, jako váš stažený soubor 768-v-ema.ckpt, config tedy přejmenujte z v2-inference-v.yaml na 768-v-ema.yaml
4. zkopírujte přejmenovaný config 768-v-ema.yaml do stejné složky jako jste kopírovali soubor 768-v-ema.ckpt:
...\stable-diffusion-webui\models\Stable-diffusion
5. spusťte soubor webui-user.bat a počkejte až se otevře webové rozhraní v prohlížeči, zde můžete zkusit zvolit vybrat model 768-v-ema.ckp z nabídky v levém horním rohu.
6. u mě se dlouho nic nedělo, v otevřeném okně cmd.exe jsem viděl, že se zaseklo stahování 3,94GB souboru, takže jsem řádek se stahováním musel odkliknout Entrem a stahování se obnovilo, po dotažení souboru se model 768-v-ema.ckpt aktivoval a bylo možné generovat obrázky.
Zatím po krátkém zkoušení začínám chápat obavy a stížnosti komunity na novou verzi Stable Diffusion 2, jelikož odstranila reference na autory, takže pokud do promptu napíšete autory, kteří ve verzi 1.5 fungovali, generované výsledky se v nové verzi 2 hodně zhorší…
Stejný prompt jsem použil u obou modelu v 1.5 (Model.ckpt) a nové verzi 2.0 ( 768-v-ema.ckpt)
very detailed portrait of a strong muscular medieval bandit leader, visible scar on his face!, intricate detailed environment, photorealistic!, intricate, elegant, highly detailed, digital painting, artstation, smooth, sharp focus, earthy color scheme, art by wlop and tyler oulton, trending on artstation, sharp focus, studio photo, intricate details, highly detailed, by greg rutkowski
Nastavení: Sampling Steps: 60 | DDIM | CFG 5,5 | Restore Faces povoleno |
Negativní prompt:
poorly drawn, extra arms, extra legs, out of frame, deformed hands, deformed fingers, deformed body



Po odstranění jmen autorů vypadá prompt pro druhý pokus takto:
very detailed portrait of a strong muscular medieval bandit leader, visible scar on his face!, intricate detailed environment, photorealistic!, intricate, elegant, highly detailed, digital painting, artstation, smooth, sharp focus, earthy color scheme, trending on artstation, sharp focus, studio photo, intricate details, highly detailed,
Nastavení stejné: Sampling Steps: 60 | DDIM | CFG 5,5 | Restore Faces povoleno |
Negativní prompt:
poorly drawn, extra arms, extra legs, out of frame, deformed hands, deformed fingers, deformed body



Jak můžete vidět i po odstranění jmen autorů z promptu má starší verze SD 1.5 stále přesvědčivě lepší výsledky než nová verze 2, těžko říct, kde udělali soudruzi chybu 🙂 ale takhle si zrovna vylepšení a pokrok nepředstavuji, uvidíme jak se situace vyvine dál, ale zatím tedy moc důvodů k optimismu není…
Subscribe
Login
0 Komentáře